Fablabs Course
2.1 Data preparation and exploration
Diagram
Descrición
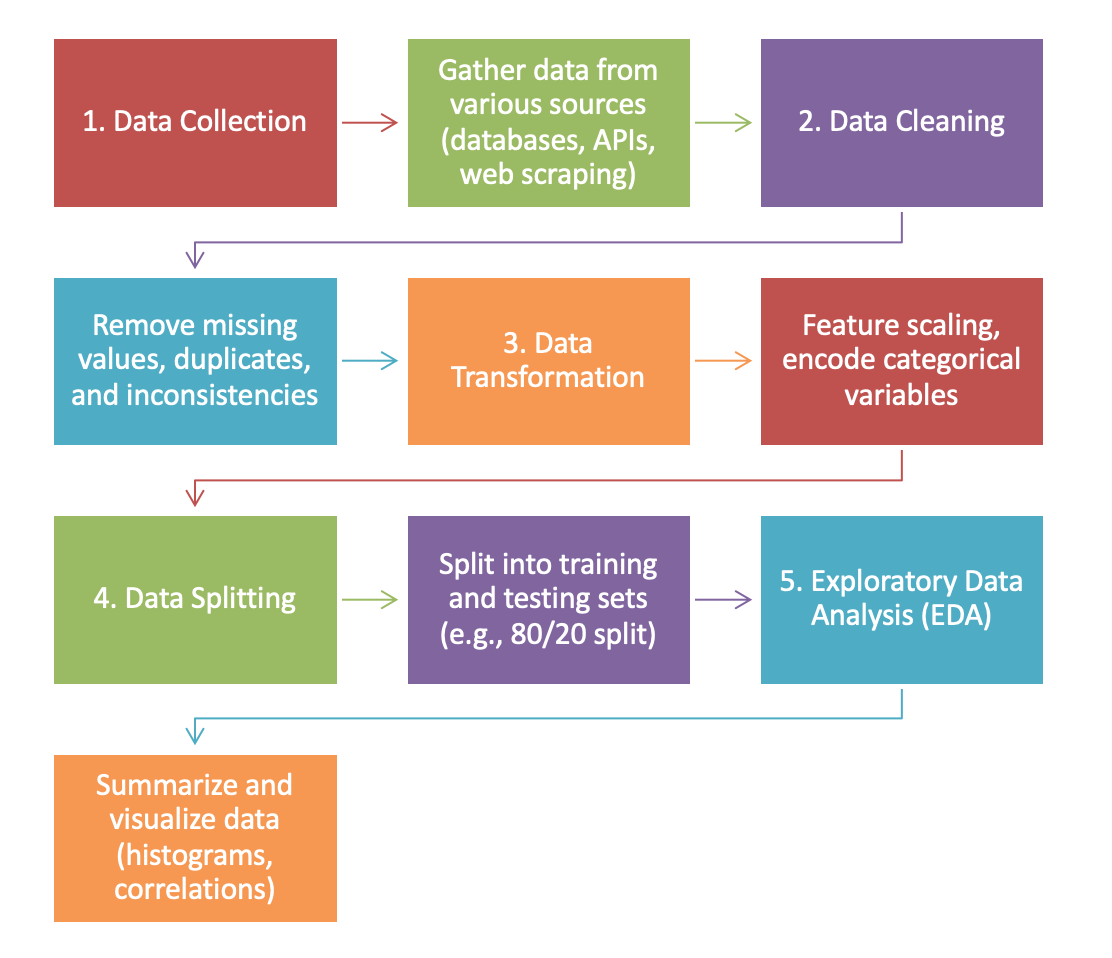
In this section of our Machine Learning Fundamentals module we will focus on the crucial steps required to prepare and understand your data before building machine learning models. This involves several key processes: data collection, cleaning, transformation, and splitting. We will also explore techniques for exploratory data analysis (EDA) to gain deeper insights into the dataset. Through practical exercises, you will learn how to collect data from various sources, clean it by handling missing values and duplicates, transform it by scaling features and encoding categorical variables, and split it into training and testing sets. Additionally, you will practice summarizing and visualizing data to uncover patterns and relationships. Mastering these steps is essential for ensuring that your machine learning models are robust and accurate. Let's begin this journey towards better data understanding and preparation!
Vídeo
[soon]
Data Preparation and Exploration
In this section we will delve into the critical steps of data preparation and exploration. Proper data preparation is essential for building robust machine learning models. In this section, we will cover data collection, cleaning, transformation, and splitting. We will also introduce exploratory data analysis (EDA) techniques to help you understand your data better. Let's get started!
1. Data Collection
Data collection is the first step in any machine learning project. This involves gathering data from various sources, such as databases, APIs, web scraping, and more. The quality and relevance of the data collected significantly impact the performance of your machine learning models.
Example:
Consider a project where you need to predict customer churn. You might collect data from CRM systems, transaction records, and customer feedback forms.
2. Data Cleaning
Once data is collected, it often contains missing values, duplicates, and inconsistencies. Data cleaning involves identifying and rectifying these issues to ensure the data is ready for analysis.
Practical Exercise:
Imagine you have a dataset with missing values and duplicates. Let's clean this data using Pandas.
import pandas as pd
# Load the dataset
data = pd.read_csv('customer_data.csv')
# Remove duplicates
data = data.drop_duplicates()
# Handle missing values by filling them with the mean
data = data.fillna(data.mean())
print(data.head())3. Data Transformation
Data transformation involves converting data into a format suitable for analysis. This includes feature scaling and encoding categorical variables.
Feature Scaling:
Feature scaling ensures that all features contribute equally to the model by normalizing or standardizing the data.
Practical Exercise:
Let's scale the numerical features in our dataset using StandardScaler from Scikit-Learn.
from sklearn.preprocessing import StandardScaler
# Select numerical features
numerical_features = data[['age', 'income', 'score']]
# Standardize the features
scaler = StandardScaler()
scaled_features = scaler.fit_transform(numerical_features)
print(scaled_features[:5])Encoding Categorical Variables:
Machine learning algorithms require numerical input. Therefore, categorical variables must be encoded into numerical values.
Practical Exercise:
Let's encode categorical variables using OneHotEncoder.
from sklearn.preprocessing import OneHotEncoder
# Select categorical features
categorical_features = data[['gender', 'city']]
# One-hot encode the categorical features
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(categorical_features).toarray()
print(encoded_features[:5])4. Data Splitting
Splitting the data into training and testing sets is crucial for evaluating the performance of your machine learning model. Typically, the data is split into 70-80% for training and 20-30% for testing.
Practical Exercise:
Let's split our dataset into training and testing sets.
from sklearn.model_selection import train_test_split
# Combine scaled numerical features and encoded categorical features
features = pd.concat([pd.DataFrame(scaled_features), pd.DataFrame(encoded_features)], axis=1)
target = data['churn']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape)5. Exploratory Data Analysis (EDA)
EDA involves summarizing and visualizing the main characteristics of the data. This step helps you gain insights and identify patterns, anomalies, and relationships within the data.
Practical Exercise:
Let's perform EDA using Pandas and Matplotlib.
import matplotlib.pyplot as plt
# Summary statistics
print(data.describe())
# Visualize the distribution of numerical features
data.hist(bins=30, figsize=(10, 8))
plt.show()
# Correlation matrix
correlation_matrix = data.corr()
print(correlation_matrix)
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
plt.imshow(correlation_matrix, cmap='coolwarm', interpolation='none')
plt.colorbar()
plt.xticks(range(len(correlation_matrix)), correlation_matrix.columns, rotation=90)
plt.yticks(range(len(correlation_matrix)), correlation_matrix.columns)
plt.show()Summary
In this section, we covered the essential steps of data preparation and exploration, including data collection, cleaning, transformation, splitting, and exploratory data analysis. Proper data preparation ensures that your machine learning models perform well and provide accurate results. In the next section, we will dive into classification algorithms, where we will learn how to build and evaluate models for predicting categorical outcomes.
Stay tuned and happy learning!
Practice
Below, you have some links to the Jupyter/Colab notebooks where you can practice the theory from this section:
Licenciado baixo a Licenza Creative Commons Atribución Compartir igual 4.0